고정 헤더 영역
상세 컨텐츠
본문
CTC(2006).pdf
0.25MB
오리지널 논문
PyTorch CRNN: Seq2Seq Digits Recognition w/ CTC | coding.vision (codingvision.net)
위 링크 중반쯤에 CTC and Duplicates Removal 있음
코랩에서 파이토치로 짧게 예시 코드 구현해놔서 보기 좋음
An Intuitive Explanation of Connectionist Temporal Classification | by Harald Scheidl | Towards Data Science
예시도 간결하고 직관적인 설명임 (Encoding, Loss calculation, Decoding로 글을 구성).
하지만 구체적이지 않고 decoding 방식을 best-path 만 제공해줌. 기본적인 개념 잡기로는 적당함.
가장 도움이 되었던 부분은 loss calculation임.

실선은 "a"가 되는 조합(path)들인데 곱해서 더해놓으면
a에 대한 score = 0.4·0.4 + 0.4·0.6 + 0.6·0.4 = 0.64
-에 대한 score = 0.6·0.6 = 0.36
그냥 이렇게 쓰기 보단 technical한 이유 때문에 "네거티브 로그" 확률을 쓴다고 함.
Breaking down the CTC Loss - Sewade Ogun's Website (ogunlao.github.io)
엄청 구체적으로 서술해놨는데 자세히 보진 않았다.
Sequence Modeling with CTC (distill.pub)
들어가며
음성 인식 과제를 해결하려고 한다. 어떤 음성 파일이 있고 대응되는 텍스트 파일이 있다고 가정하자. 하지만 불행하게도 어떻게 텍스트 파일에 있는 글자와 음성이 정렬(align)되는지 모른다. 이렇게 문제가 꼬인다.
여기서 다음과 같이 생각해본다:
1) rule-based hard coding을 한다고 하면, 각 음성 특징(말하기 속도 등)이 다르므로 매우 불안정할 것이다.
2) 수작업으로 각 음성에 글자를 대응시키는 방법은 너무나 자원소모적이다. 특히나 빅데이터를 다룬다고 하면 천문학적인 비용이 들 것이다.
비단 이러한 문제는 음성 인식에서만 있는 것은 아니다. 아주 많은 과제에서 등장한다. 이미지에서 손글씨(필기체) 인식이라던가, 비디오에서 행동 라벨링이라던가.
여기서 CTC 가 입력과 출력의 정렬 관계를 모를 때 유용하게 사용될 수 있다.
좀 더 formal하게 문제를 접근해보자.
오디오 파일: X = [x1, x2, ... , x(T)]
텍스트 시퀀스: Y = [y1, y2, ... , y(U)]
우리의 목표는 X 와 Y의 적절한 매핑이다.
이 때, 문제를 더 복잡하게 하는 요소들이 있다:
1) X, Y의 길이는 가변적이다.
2) X와 Y의 길이 간의 비율도 가변적이다.
3) X와 Y의 정확한 정렬 관계를 모른다.
CTC 알고리즘으로 우리는 이 문제를 해결할 수 있다. 주어진 X에 대해서, 가능한 모든 Y의 분포를 안다면, 우리는 이 분포를 활용해서 (1) 가장 그럴듯한 Y을 추론하거나 (2) 주어진 Y에 대해서 확률을 평가할 수 있다. (가능한 모든 정렬 관계의 확률을 더하면 됨)
CTC 알고리즘
CTC 알고리즘은 주어진 X에 대해서 Y의 확률을 배정할 수 있다. 이 확률을 계산하는 데에 중요한 것은 CTC가 입력과 출력의 정렬관계를 어떻게 취급하는지 아는 것이다. 가장 먼저 우리는 정렬 관계에 대해서 알아보고 난 뒤, 이를 loss 함수와 추론에 어떻게 활용할 수 있는지 볼 것이다.
정렬 관계
우리는 X와 Y의 정렬 관계에 대한 확률을 알기 위해서는 정렬 관계에 대해서 알아야 한다.
가장 베이직한 접근법을 고려해보자.
예시> X의 길이: 6 ; Y = [c, a, t] ; 각 입력 스텝마다 출력 글자를 정렬해주고 중복되는 것 하나로 뭉치기.

이러한 접근법은 2가지 문제점이 있음:
1) 모든 스텝에 어떤 출력을 배정하는 건 별로 좋은 아이디어가 아닌 경우가 꽤 많음. 음성인식을 예로 들자면, 입력에서 무음인 경우도 있을텐데 그럴 때 출력 글자를 강제로 하나 배정하는 건 좋지 않음.
2) 같은 글자가 연속되서 나타나게 되면 대처할 방법이 없음. 예를 들어 [h, h, e, l, l, l, o]는 위 접근법에 의하면 우리가 의도하는 바는 "hello"임에도 "helo"가 될 것임.
이러한 문제점을 해결하기 위해서 CTC는 허용되는 출력의 집합에 "blank token"을 추가함. ϵ 라는 기호로 이것을 지칭해보자. ϵ 는 어떠한 것에도 대응되지 않고 출력에서 제거될 것임.
CTC에서 허용되는 정렬 출력은 입력의 길이와 같아야 하는데, 중복되는 것을 합치고 ϵ 를 제거하면 다음과 같다:

이러한 방식으로 우리는 hello와 helo를 구분할 수 있을 것이다.
다시 입력의 길이가 6이고 출력이 [c, a, t]인 위 예시로 돌아가보자. 유효한 정렬과 유효하지 않는 정렬의 예시는 다음과 같다:

이러한 CTC 정렬은 다음과 같은 특징을 가진다:
1) X와 Y간에 허용되는 정렬은 monotonic하다. 우리가 다음 입력으로 넘어갈 때, 우리는 대응되는 출력을 keep하거나 다음 것으로 넘어갈 수 있다.
2) X와 Y간에 관계는 다:1 관계이다. 1개 이상의 입력은 1개의 출력에 대응될 수 있지만 반대는 성립하지 않는다.
3) Y의 길이는 X의 길이보다 길 수 없다.
손실 함수
CTC 정렬은 각 타임 스텝마다의 확률 분포로부터 출력 시퀀스의 확률로 넘어가는 자연스러운 방법을 제시한다.

1) 예를 들어 음성파일의 스펙트로그램 같은 입력으로 부터 시작해보자.
2) 입력은 RNN에 입력된다고 하자.
3) 그러면 RNN은 pt(a | X)라는 확률을 뽑아내는데, 이는 "각 입력 스텝의 출력에 대한 확률 분포"이다. 만약 가능한 출력 집합이 {h, e, l, o, ϵ}라고 한다면 예를 들어 h: 0.95, e: 0.01, l: 0.01, o: 0.01, ϵ: 0.02 따위로 나온다.
4) 이러한 확률 분포를 가지고, 우리는 "각기 다른 시퀀스 출력에 대한 확률 분포"를 알아볼 수 있다.
5) 정렬에 대한 중복 합치기 및 ϵ 제거 등을 수행하면 (marginalizing) 출력에 대한 분포를 얻게 된다.
더 엄밀히 (수학적으로) 다뤄보자면 한 (X, Y) 쌍에 대한 CTC 정렬의 목표는:
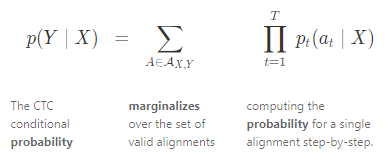
CTC로 훈련되는 모델은 전형적으로 RNN을 사용하여 타임스텝 별 확률을 구한다 (즉, pt(at | X)). RNN은 입력의 문맥정보를 고려하기 때문에 일반적으로 잘 작동하긴 하지만 우리는 다른 알고리즘을 사용해도 된다.
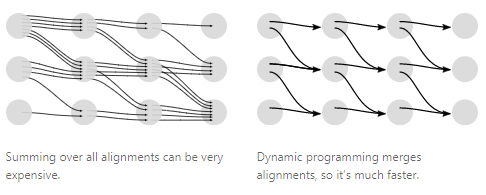
주 의: 조심하지 않으면 CTC는 매우 큰 자원을 소모할 수도 있다. 가장 직관적인 방법으로 모든 정렬 방법에 대해서 계산해보는 것이다. 문제는 정렬의 조합이 너무 많을 수 있다. 그래서 대부분의 경우에는 이 방법은 너무 느릴 것이다.
다행히도 우리는 이 손실 함수를 동적 프로그래밍 알고리즘을 통해 더 빠르게 계산할 수 있다. 만약 두 정렬이 같은 타임스텝에 같은 출력에 도달했다면 둘을 합치는 방법이다.
우리는 Y 내의 어떠한 토큰 앞이나 뒤에 ϵ 이 올 수 있으므로, ϵ 이 포함된 시퀀스를 활용해 알고리즘을 설명하는 편이 더 쉬울 것이다.
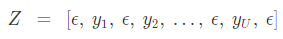
시퀀스 Z는 처음과 끝에, 그리고 각 글자 사이에 ϵ 가 위치한 Y이다.
∝를 주어진 노드에서 합쳐진 정렬의 CTC 점수라고 하자. 더 정확하게는, ∝s,t 는 타임스텝 t 가 지난 후의 부분 시퀀스 Z1:s 의 CTC 점수라고 할 수 있다. 아래에서 보겠지만, 우리는 최종 CTC 점수인 P(Y | X) 를 마지막 타임스텝에 있는 ∝로 계산할 것이다. 우리가 이전 타임스텝에서의 ∝ 값을 알고 있는 한, 우리는 ∝s,t 를 계산할 수 있다.
아래 그림은 동적 프로그래밍 알고리즘을 통해 계산된 예시입니다. 가능한 모든 유효한 정렬은 선으로 연결되어 있습니다.

여기서 유효한 시작점과 유효한 최종점은 두 개입니다. 왜냐하면 시작점과 최종점에 위치한 ϵ 는 optional하게 위치하기 때문입니다. 총 확률은 두 최종점 노드의 합계입니다.
이러한 손실 함수르 바탕으로 우리는 모델을 훈련시킬 수 있습니다. 그냥 있는 그대로 손실 함수를 쓰기 보다, 우리는 네거티브 로그 함수를 활용합니다.
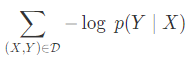
추 론
우리는 모델을 훈련시켜 주어진 입력의 가장 likely한 출력을 찾고 싶습니다. 이를 위해 우리는 다음과 같은 문제를 풀어야 합니다:
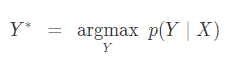
(시간이 없는 관계로.. 후 략)
텐서플로 백엔드 ctc_decode API
tf.keras.backend.ctc_decode - TensorFlow Python - W3cubDocs
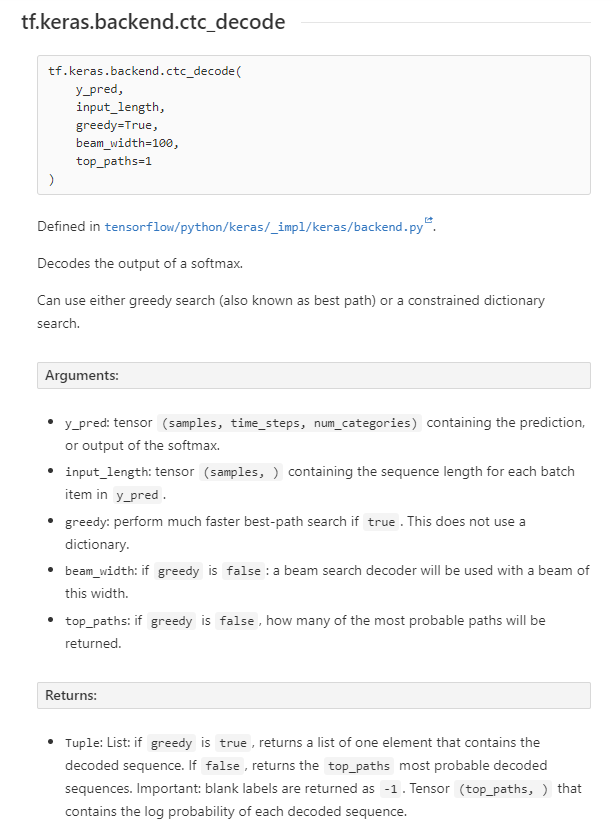
소프트맥스 출력값을 해독해준다
그리디 검색 혹은 제약된 사전 검색으로 사용 가능하다
CMU 강의
https://youtu.be/c86gfVGcvh4
Takeaways
1) Enforce two constraints: (1) target sequences are only considered as output of probability (RNN모델이든 뭐든 확률값을 출력하는 시스템에 일정한 시퀀스가 답으로 제시된다는 제약을 부여; e.g. 이 음성파일의 답은 반드시 /B/ /IY/ /F/ /IY/ 의 순서로 출력되어야 한다) (2) when the answers are ordered, the path can only start from the top-left and end at bottom-right; also, the nodes flow from top to bottom where each node is connected with two previous nodes.
2) Take into account that 'blank' can be an answer too.
The rest is the same-old process (feed forward, backward, calculate the error, and update the system)
Prerequisite concept: Viterbi algorithm (or any other dynamic algorithm), Bayesian probability
'Coding > Sound' 카테고리의 다른 글
| Understanding automated assessment of speaking with Jing Xu (0) | 2021.12.03 |
|---|---|
| 4. Custom Audio PyTorch Dataset with Torchaudio (0) | 2021.06.18 |
| Query, Key, and Value in Attention (0) | 2021.06.10 |
| Transformer (0) | 2021.06.03 |
| Attention (0) | 2021.05.31 |




