고정 헤더 영역
상세 컨텐츠
본문
Title: Attention Is All You Need
Authors: Vaswani et al. (2017)
제목이 비틀즈의 "All you need is love"를 오마주한 부분이 상당히 인상적이다.
초 록
대부분의 시퀀스 변환(transduction) 모델은 복잡한 순환신경망 혹은 합성곱신경망에 기반을 두고 인코더와 디코더를 가진 형태이다. 가장 좋은 성능을 보이는 모델들 또한 어텐션 매커니즘을 통해 인코더와 디코더를 연결한다. 우리는 트랜스포머(Transformer)라고 불리는 오로지 순환신경망과 합성곱신경망을 전혀 사용하지 않고 어텐션 매커니즘으로만 작동되는 간단한 신경망을 제안한다. 이 모델들은 두 개의 기계 번역 과제를 수행하는 실험에서 성능은 더 뛰어나면서도 병렬 처리(parallelizable)가 가능하고 훈련 시간이 현저하게 적게 드는 것을 보여주었다. 우리 모델은 WMT 2014 영어-독어 번역 과제에서 앙상블 기법을 포함한 기존의 가장 뛰어난 결과를 뛰어넘는 28.4 BLEU를 달성하였는데 이는 2 BLEU가 넘는 격차이다. WMT 2014 영어-불어 번역 과제에서 우리의 모델은 단독 모델로서 가장 뛰어난 41.8 BLEU라는 신기록을 확립하였는데, 이는 문헌에 보고된 좋은 모델들의 훈련비용의 극히 일부분 정도 수준인 8개의 GPU로 3.5일 동안 훈련한 결과이다. 우리는 트랜스포머가 대량 및 소량 훈련 데이터인 조건에서 영어 구성소(constituency) 파싱(parsing) 과제에 성공적으로 적용함으로서 다른 과제에도 일반화가 잘 됨을 보여주었다.
1. 들어가며
순환신경망은, 특히 LSTM [13]와 GRU [7]는, 시퀀스 모델링과 언어 모델링과 기계 번역 같은 시퀀스 변환 문제[35, 2, 5]의 최첨단 접근법으로 견고히 확립되었다. 그 이후로 순환 언어 모델과 인코더-디코더 모델구조의 경계를 넓히려는 여러 노력이 있어 왔다 [38, 24, 15].
순환 모델은 전형적으로 입력과 출력 시퀀스의 기호들(symbol)의 위치에 따른 계산을 고려(factor)한다. 타임스텝에 대해서 입출력의 위치들을 정렬하면서 순환 모델은 이전 은닉 상태(hidden state) h_(t-1)와 위치 t에 대한 입력의 함수로서의 은닉 상태 h_(t)의 시퀀스를 생성한다. 이런 본질적인 시퀀스적인 성질은 훈련 표본들(training examples) 간의 병렬화(parallelization)을 사전에 차단하는데, 이는 시퀀스 길이가 길어질수록 여러 표본들에 걸친 배치(batch) 추출을 제한하는 메모리의 제약 때문에 더 심각해진다. 최근 연구는 분해(factorization) 기법[21]과 조건적 연산(conditional computation)[32]을 통해 연산 효율성의 상당한 향상을 달성하였는데, 조건적 연산의 경우 모델 성능까지도 향상시켰다. 하지만, 시퀀스적 연산의 원천적인 제약은 여전히 남아있다.
어텐션 매커니즘은 다양한 과제에서의 시퀀스 모델링과 시퀀스 변환(transduction) 모델링의 핵심적인 부분이 되었고, 입력과 출력 시퀀스 간의 거리와 무관하게 의존성을 모델링할 수 있도록 하였다[2, 19]. 그렇지만, 소수의 경우만 제외하고[27] 그러한 어텐션 매커니즘은 순환신경망과 함께 사용되었다.
본 논문에서 우리는 트랜스포머를 제안한다. 이는 순환성을 배제하고 순전히 어텐션 매커니즘에만 의존하여 입력과 출력의 전역 의존성(global dependency)을 이끌어내는 모델 구조이다. 트랜스포머는 상당히 더 많은 병렬화와 겨우 8개의 P100 GPU를 12시간 동안 훈련함으로써 현 수준에서 최고조에 달하는 번역 품질을 가능케 한다.
2. 배 경
(본 논문의 취지와 같이) 시퀀스 연산을 줄이려는 목표는 나아가 Extended Neural GPU[16], ByteNet[18], ConvS2S[9]의 기반을 구성하는데, 이 모델들은 공통적으로 합성곱신경망을 기본적인 구성 요소로 사용하여 모든 입력과 출력의 위치에 대한 은닉층의 특징(hidden representation)을 병렬적으로 계산한다. 이들 모델이 임의의 두 개의 입력 혹은 출력 위치로부터 신호들을 연관시키기 위해 필요로 하는 연산량은 위치간의 거리에 비례하여 증가하는데, ConvS2S의 경우 선형적으로(linearly) 증가하고 ByteNet의 경우 대수적으로(logarithmically) 증가한다. 이는 거리가 멀리 떨어져 있는 위치 간의 의존성을 학습하는 것을 더욱 어렵게 만든다[12]. 트랜스포머에서 이 연산량은 상수(constant) 연산량으로 감소된다. 한편, 어텐션 가중치가 적용된 위치들을 평균냄으로써 효과적인 해상도의 감소를 비용으로 치루긴 하는데, 이는 섹션 3.2.에서 서술된 다중 헤드 어텐션(Multi-Head Attention)으로 대응하려고 한다.
간혹 내적 어텐션(intra-attention)이라고 불리는 셀프 어텐션(self-attention)은 해당 시퀀스의 특징(representation)을 연산하기 위해 단일 시퀀스의 다른 위치들을 연관짓는 어텐션 매커니즘이다. 셀프 어텐션은 텍스트 이해(reading comprehension), 추상적 요약(abstractive summarization), 텍스트 함의(textual entailment), 과제 독립적인 문장 의미 학습(learning task-independent sentence representation)과 같은 여러 과제에서 성공적으로 사용되었다 [4, 27, 28, 22].
종단 간(end-to-end) 메모리 신경망은 시퀀스 정렬 순환(sequence-aligned recurrence) 대신에 순환 어텐션 매커니즘(recurrent attention mechanism)에 기반을 두는데, 간단한 말로(simple-language) 제기되는 문제를 답하는 과제와 언어 모델링 과제에서 잘 수행하는 것을 보여주었다.
우리가 아는 한, 트랜스포머는 시퀀스 정렬 RNN 혹은 CNN을 사용하지 않고 전부 셀프 어텐션으로 작동하여 입력과 출력의 특징을 연산하는 최초의 시퀀스 변환 모델이다. 다음 섹션에서 우리는 트랜스포머를 설명하고, 셀프 어텐션을 사용한 동기를 설명하며, 트랜스포머가 [17, 18]과 [9]와 같은 모델보다 뛰어난 장점을 논의할 것이다.
3. 모델 구조
대부분의 경쟁력 있는 시퀀스 변환 모델은 인코더-디코더 구조를 가지고 있다 [5, 2, 35]. 인코더는 기호 표현(symbol representation)인 입력 시퀀스 (x_(1), ..., x_(n))를 연속적인 표현 z = (z_(1), ..., z_(n))에 매핑해준다. z가 주어졌을 때, 디코더는 기호로 이루어진 출력 시퀀스 (y_(1), ..., y_(n))를 한 번에 하나씩 생성한다. 각 스텝마다 모델은 자기회귀적(auto-regressive)이어서 현 단계의 출력을 생성할 때 이전 단계에서 생성된 기호를 추가적인 입력으로 받아 사용한다.
트랜스포머는 인코더와 디코더 모두 (1) 스택된 셀프 어텐션과 (2) 점별(pointwise) 완전연결층으로 이루어져 다음과 같은 구조로 이루어져 있다. (<그림 1>의 좌측은 인코더, 우측은 디코더다)

3.1. 인코더와 디코더 스택
인코더: 인코더는 N = 6 개의 동일한 층의 스택(stack: 쌓인 구조)으로 이루어져 있다. 각 층은 두 개의 하위층(sub-layer)을 가진다. (1) 첫번째 하위층은 다중 헤드 셀프 어텐션(multi-head self-attention mechanism)이고 (2) 두번째 하위층은 간단한 점별 완전연결 순전파 신경망(point-wise fully connected feed-forward network)이다. 우리는 각 하위층에 대해서 잔차 연결(residual connection)[11]과 층 정규화(layer normalization)[1]을 도입하였다. 즉, 각 하위층의 출력은 LayerNorm(x + Sublayer(x))이다. (역자 덧글: 하나의 수식으로 표현하면 이렇다는 말이다) 잔차 연결을 하기 위해서 임베딩 층을 포함한 모든 하위층은 동일한 차원 d_(model) = 512으로 출력을 만든다.
디코더: 디코더 또한 N=6 개의 동일한 층의 스택으로으로 이루어져 있다. 디코더에서는 인코더 층에서 있던 하위층 2개와 더불어 추가적으로 세번째 하위층을 삽입하는데 이는 인코더 스택의 출력에 대해서 다중 헤드 어텐션을 수행한다. 인코더와 비슷하게 우리는 잔차연결과 층 정규화를 각 하위층에 도입하였다. 우리는 또한 각 위치가 잇따르는 위치를 보는(attending) 것을 방지하기 위해 디코더에 있는 셀프 어텐션 하위층에는 일부 수정을 가했다. 이 마스킹(masking)은 출력 임베딩이 위치 하나만큼 오프셋(offset)된다는 사실과 함께 작용하여 위치 i에 대한 예측이 이미 알고 있는 출력(i보다 작은 위치에 있는 출력들)에 대해서만 의존함을 보장한다.
3.2. 어텐션
어텐션 함수는 쿼리(query) 및 키-값(key-value) 쌍을 출력과 매핑하는 것이라고 설명될 수 있다. (이 때, 쿼리, 키, 값, 출력은 모두 벡터이다.) 출력은 값들의 가중치가 적용된 합(weighted sum)으로 연산되는데, 각 값에 적용된 가중치는 쿼리와 그에 대응하는 키의 호환성 함수(compatibility function)로 연산된다. (Additional Material [1] 참고)
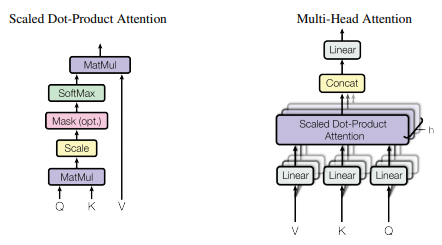
3.2.1. 스케일 된 내적 어텐션
우리는 이 특정한 어텐션을 "스케일 된 내적 어텐션"이라고 부르기로 했다 (<그림 2> 참고). 입력은 (1) 차원 d_(k)의 쿼리 및 키와 (2) 차원 d_(v)의 값(value)으로 이루어져 있다. 우리는 모든 키에 대해서 쿼리의 내적을 연산하고, 각각 root(d_(k))로 나누고, 값(value)에 대한 가중치를 구하기 위해 소프트맥스 함수를 적용한다. (Additional Materials [2] 참고)
실제적으로, 우리는 어텐션 함수를 행렬 Q에 하나로 패킹된 쿼리들의 집합에 대해서 동시에 어텐션 함수를 연산한다. 키와 값 또한 행렬 K와 V로 각각 패킹되어있다. 우리는 출력을 다음과 같은 공식을 통해 연산한다: (역자 주: 이 수식 하나로 어텐션이 함축적으로 표현되었다)

가장 흔하게 사용되는 어텐션 함수는 가법 어텐션 (additive attention) [2]과 승법 어텐션 (dot-product (multiplicative) attention)이다. 승법 어텐션은 1/sqrt(d_(k))로 스케일하는 요소를 제외하고 우리의 알고리즘과 동일하다. 가법 어텐션은 하나의 은닉층을 가진 순전파 신경망을 사용하여 호환성 함수를 연산한다. 두 어텐션 함수는 이론적으로 복잡도가 유사하지만, 실제적으로는 승법 어텐션이 고도의 최적화된 행렬곱 코드를 사용하여 구현될 수 있기 때문에 더욱 빠르고 공간 효율적이다.
비록 작은 값의 d_(k)인 경우에는 두 어텐션이 비슷한 수행 능력을 보이지만, 큰 값의 d_(k)에 대해선 스케일링 없이도 가법 어텐션이 승법 어텐션의 성능을 뛰어넘는다 [3].
Reference
Paper:
Paperswithcode: Transformer Explained | Papers With Code
PDF file:
Code:
Keras Implementation: (1) Text classification with Transformer (keras.io)
PyTorch Implementation: (1) transformer-pytorch/transformer.py at e7266679f0b32fd99135ea617213f986ceede056 · tunz/transformer-pytorch (github.com) (starts from line 201) (2) How to code The Transformer in PyTorch (floydhub.com) (Blog; + explanation)
Video:
동빈나 YouTube: [딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습) - YouTube
Additional Materials:
[1] 어텐션 메커니즘과 transfomer(self-attention) | by platfarm tech team | mojitok | Medium
[2] Scaled Dot-Product Attention(transformer) | 易学教程 (e-learn.cn) (스케일 된 내적 어텐션 보충 자료)
[3]
Attention Is All You Need_1706.03762v5.pptx
3.13MB
[4] self-attention gif src: Illustrated: Self-Attention. Step-by-step guide to self-attention… | by Raimi Karim | Towards Data Science colab version: https://colab.research.google.com/drive/1rPk3ohrmVclqhH7uQ7qys4oznDdAhpzF

[5] fengxinjie/Transformer-OCR (github.com) 트랜스포머를 OCR 과제에 적용함.
'Coding > Sound' 카테고리의 다른 글
| 4. Custom Audio PyTorch Dataset with Torchaudio (0) | 2021.06.18 |
|---|---|
| Query, Key, and Value in Attention (0) | 2021.06.10 |
| Attention (0) | 2021.05.31 |
| SCE+TTS (0) | 2021.05.28 |
| BK-tree search (0) | 2021.05.27 |




