FOTS
한국어 텍스트 탐지 및 인식을 위한 프로젝트
(딥러닝을 활용한 OCR 혹은 STR)

문제 정의:
딥러닝을 활용하여 이미지 형식으로 존재하는 텍스트를 탐지하고 인식하는 프로젝트. 이미지 내부에서 존재하는 텍스트는 다양한 변형(가령 폰트, 크기, 비율, 기울기 등)이 존재하므로 어려운 과제이다. 또한 이는 컴퓨터 비젼과 NLP를 합친 문제이기 때문에 실생활에서 여러 응용이 가능하다. (자율주행, 풍경 이해, 문서 분석 등)
좀 시간 걸리더라도 [2] 참고하여
FOTS ipynb 이해하고 돌려보기.
Table of Contents
6개 쥬피터노트북
Recognition (5)
data_generator (2)
detection_icdar (4)
detection_synthtext (3)
fots_eda (1)
inference (6)
1. fots_eda
Dataset
ipynb 작성자는 [2a]에서 밝힌 바처럼, ICDAR 2015 데이터를 가져다 썼다. 800K의 합성 이미지와 1K의 실제 이미지이다. 데이터의 타겟 언어는 영어이다.
하지만 본 프로젝트는 ICDAR 2019 Robust Reading Challenge on Multi-lingual scene text detection and recognition (MLT) 안에 있는 한국어 1K 이미지와 SynthText 이미지 40K 이미지를 사용할 것이다.

733,938,1080,996,1104,1129,746,1047,Korean,문을닉닫아주세요
669,667,1016,700,1055,951,729,911,Korean,냉.난방중
1475,335,1556,332,1620,754,1535,742,Korean,출입문
1337,335,1412,341,1470,739,1389,730,Korean,출압문
1888,652,3986,652,3965,1106,1897,912,Korean,###
1935,948,2433,1003,2429,1124,1944,1075,Latin,###
2493,1003,3025,1057,3021,1190,2467,1130,Latin,###
3068,1069,3883,1148,3866,1287,3077,1190,Latin,###
14,146,14,108,37,108,37,146,Korean,수
58,134,46,101,103,80,115,112,Korean,있는
3,183,-5,161,46,142,54,164,Korean,수행원
59,162,59,133,71,133,71,163,Korean,등
이미지 크기, 바운딩 박스 크기 분포 등 어쩌고저쩌고 생략.
2. data_generator
synthtext 데이터셋을 ICDAR 형식으로 변환해주는 파일인듯. ICDAR 1000장만 일단 해볼 거니까 생략.
3. detection_synthtext
이 파일에서는 먼저 합성된 이미지에 대해서 선행적으로 훈련시키고 난 뒤에 icdar에 훈련시키는 듯 함. 합성 이미지 훈련시킬 때는 (1) backbone으로 ResNet50를 사용, (2) pretrained on imagenet weight을 활용.
4. detection_icdar
위 파일 detection_synthtext 같은 경우에는 레이블링 형식이 따로 있어서 ICDAR의 형식에 맞춰주는 코드가 있었는데, 이 코드의 경우에는 (찐) ICDAR 파일을 다루기 때문에 그런 변환 코드가 없다. 1000개의 이미지와 레이블링이라서 얼마나 정확도가 좋게 나올지는 미지수다.
5. recognition
CRNN 모델 비슷함. 일단 훈련 시켜야 하니까 이에 필요한 데이터 만들고 훈련시키는 듯.
6. inference
훈련된 가중치 가져와서 추론 실시하는 코드. (conclusion도 서술되어 있음)
Paper Reading
Title: FOTS: Fast Oriented Text Spotting with a Unified Network
(직역하자면 "통합된 신경망 구조로 되어 여러 기울기의 텍스트에 대해 빠르게 탐지하는 모델")
Authors: Xuebo Liu et al. (2018)
중국 선전과기대 출신들.
초 록
문서 분석 커뮤니티에서 incidental scene text spotting (incidental: 고정된 방식 아니고 매 순간 하는)은 가장 어렵고 가치 있는 과제 중 하나로 간주된다. 대부분의 기존 방식은 텍스트 탐지(detection)과 인식(recognition)을 다른 과제로 취급한다. 본 논문에서 우리는 (탐지와 인식이 동시에 이루어져서 탐지와 인식이라는 상호 보충적 과제 간의 연산과 시각적 정보를 공유하는) 통합된 종단 간 훈련 가능한 모델인 FOTS를 제안한다. 특히, RoIRotate는 탐지와 인식 간의 컨볼류션 특징을 공유하기 위해 도입되었다. 우리의 FOTS 모델은 합성곱 방식에서 이득을 취하여 (1) 탐지 신경망 모델 하나만 돌리는 것보다 연산량의 증가가 거의 없고 (2) 통합된 훈련 방식으로 더 일반화된 특징을 배워 탐지와 인식을 두 단계로 나눠서 하는 방식보다 더 좋은 성능을 보인다. ICDAR 2015, ICDAR 2017 MLT, ICDAR 2013 데이터셋에 대한 실험으로 확인한 바, 우리의 방식은 SOTA 방식들보다 훨씬 더 좋은 성능을 보이고 있는데 (ICDAR 2015 과제에서 기존 SOTA 방식보다 5% 이상 뛰어넘고 22.6fps 속도로 작동), 이는 실시간으로 oriented 텍스트에 대해 탐지 및 인식(spot)할 수 있는 최초의 모델인 것이다. (본인들 모델 성능 어필어필 중)
1. 도 입 (생략)

2. 관련 연구 (생략)

<그림 2>에 대한 Note
- Shared Convolutions에서 1/32 크기로 줄여졌다가 1/4로 upscale 실시함 (motivation: 작은 textbox 잡기 위해)
- Text Detection Branch는 FCN에 기반함
- RoIRotate는 region proposals를 가로세로 비율 유지한 채 고정된 높이로 만들어줌 (그래야 CNN에 들어감) + Affine transformation & padding
- Text Recognition branch는 CRNN 구조 차용 (CNN + RNN + CTC)

3. 방법론 (Methodology)
FOTS는 종단 간 훈련 가능한 프레임워크로 자연적인 풍경 이미지로부터 모든 단어에 대해 탐지 및 인식을 동시에 한다. 이 모델은 4 부분으로 이루어져 있다: (1) 공유된 합성곱 특징, (2) 텍스트 탐지 branch, (3) RoIRotate 공정, (4) 텍스트 인식 branch.
3.1. 전체 구조
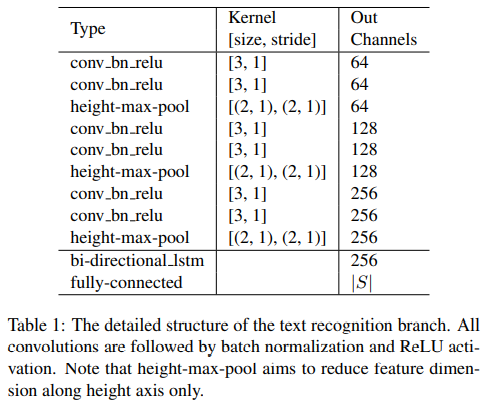
<그림 2>에 전반적인 구조가 그려져 있다. 텍스트 탐지 branch와 텍스트 인식 branch는 합성곱 특징을 공유하는데 공유된 합성곱 레이어의 구조는 <그림 3>에 서술되어 있다. 공유된 컨볼루션 신경망의 backbone은 ResNet-50이다 [12]. FPN에 영감을 받아서 [35] 우리는 저수준(low-level) 특징 맵과 고수준(high-level) 시멘틱 특징 맵을 concatenate하였다. 공유된 컨볼류션 레이어가 만들어낸 특징 맵의 해상도는 원본 이미지의 1/4 수준이다. 텍스트 탐지 branch는 공유된 컨볼루션을 활용하여 텍스트에 대한 dense한 픽셀 별 예측을 출력한다. 탐지 branch에 의해 만들어진 oriented 텍스트 영역 제안을 가지고 RoIRotate는 그에 대응되는 shared features를 고정된 높이의 representations로 변환하는데, 이 때 원본 이미지의 가로 세로 비율은 유지한다. 최종적으로, 텍스트 인식 branch는 제안된 구역에서 단어들을 인식한다. CNN과 LSTM은 텍스트 시퀀스 정보를 인코딩하기 위해 도입되었고, 이후 CTC 디코더가 따라오는 순서이다. 우리의 텍스트 인식 branch의 구조는 <도표 1>에 제시되어 있다.
정리하자면...
(1) ResNet-50을 기반으로하는 conv layers 통과
a. 탐지와 인식에 모두 공유됨
b. 저수준 고수준 콘캣됨 (like FPN)
c. 원본 이미지 1/4 사이즈
(2) detection에서는 픽셀별 예측, region proposals 만들어냄
(3) RoIRotate를 통해 고정된 높이로 통일시킴
(4) recognition 실시. (CNN + LSTM + CTC)
3.2. 텍스트 탐지
[53 EAST 모델, 15]에 영감을 받아 우리는 텍스트 탐지기에 완전 합성곱(fully-convolutional) 신경망을 적용한다.
3.3 RoIRotate

Reference
[1] PyTorch Implementation (original author): jiangxiluning/FOTS.PyTorch: FOTS Pytorch Implementation (github.com)
[2] a. Fast Oriented Text Spotting (FOTS) | by sugam verma | Apr, 2021 | Medium (작성자의 설명과 곁들인 포스팅)
b. sugam95/FOTS (github.com) (ipynb로 되어 있어서 코랩으로 돌릴까 싶다)
eda 파일 제외한 코드: (eda 파일에 결과 출력 부분에서 사진이 많아서 10MB가 넘는다)
[3] ICDAR 2019 Overview - ICDAR 2019 Robust Reading Challenge on Multi-lingual scene text detection and recognition - Robust Reading Competition (uab.es) (본 프로젝트에서 사용하는 한국어 데이터)
[4] SynthText Visual Geometry Group - University of Oxford (ipynb 작성자가 활용한 ICDAR 2015 합성 이미지 출처)
[5] 믿어왔던 쥬피터노트북이 안 되면서 찾게 된 깃헙: RaidasGrisk/tf2-fots: FOTS text detection and recognition (github.com)